Getting started
Introduction
Exerica is a radical new solution to the age-old problem of data extraction for financial modelling and analysis.
Exerica delivers automatic data sets to the end-user via REST API. It accepts any data point in a publication as an input, and returns its best match (i.e. a data point with the same meaning and context) in other documents sourced from the same publisher. Exerica’s state-of-the-art technology provides instant access to complete data series.
To get started please register here. This will direct you to the Exerica web application which can be used in tandem with the Excel plug-in and Data Sets API.
How does it work?
Deciphering corporate reports has always been painstaking. Every report challenges the analyst with information presentation, and numbers, assumptions, and formulas scattered throughout the document. These can vary from quarter to quarter and year to year for every company – and that is before thinking about formatting, styles and corporate phraseology, which can vary from year to year, project to project, and executive to executive.
Exerica has navigates around this information chaos. It starts with structuring numerical data in tables take account of the mathematical relationships between numbers. Once every number is put “in relation to” other numbers, linking all data across the report becomes much simpler.
This means Exerica extracts the full accounting structure from a company report – a solution that no one has managed to do until now. What Exerica sees is the original hierarchical structure of a company’s accounts, and not a miasma of words and numbers.
The resulting data structure can then be accurately linked with like structures from any other financial report – from one company across time, to a range of companies in a market sector. Every item can be matched against the same data in other reports with exactly the same analytical and accounting meaning.
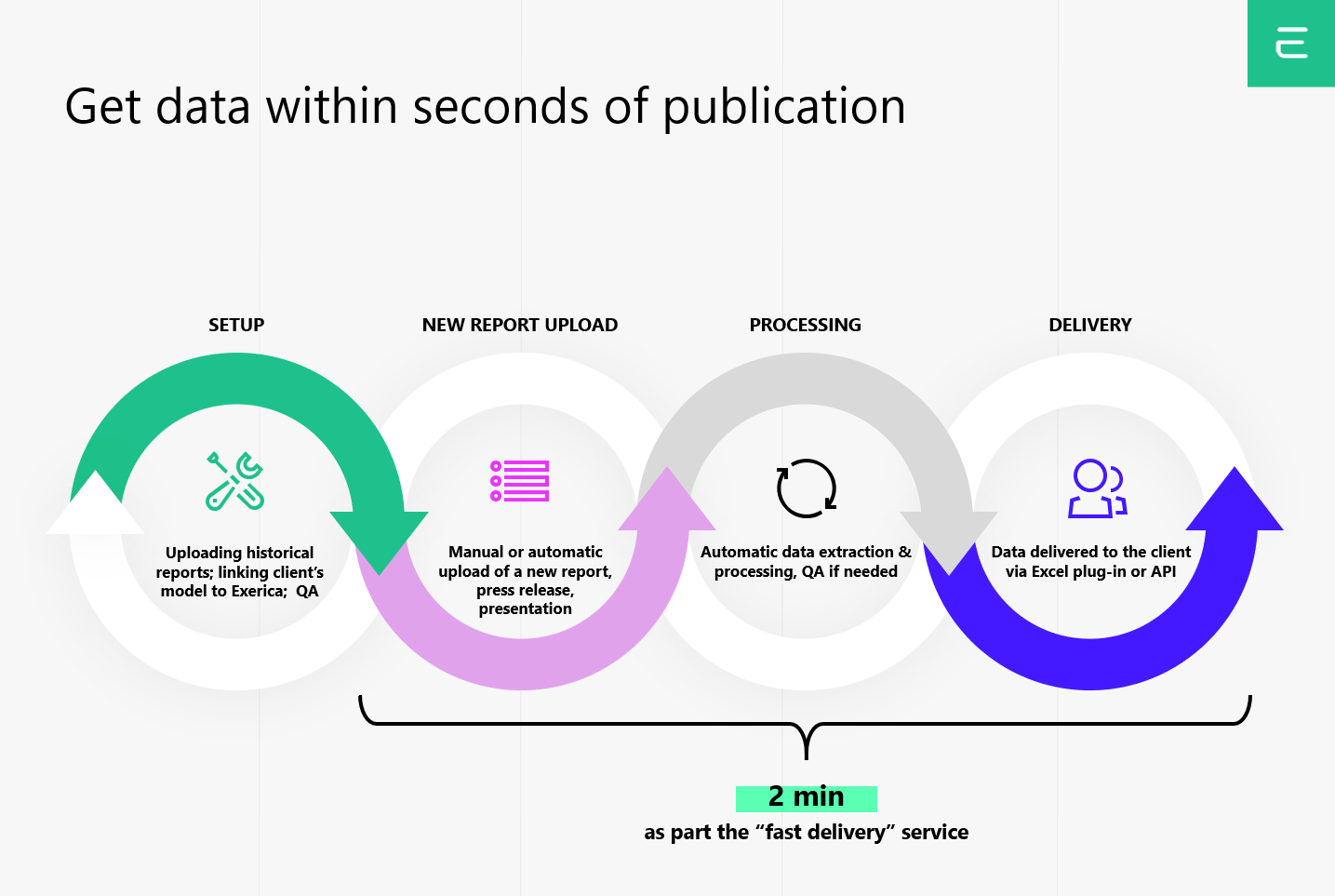
It normally takes from one to five minutes to process a document with Exerica’s algorithms. As part of an automatic process all numerical data is extracted, analysed and structured to make it accessible to end-users via our API and Excel plugin.
The key processes are these:
- Optical recognition is the greatest variable in the process. It usually takes a few seconds to extract text from a pdf with a text layer (the vast majority of financial publications) but may take a few minutes to process scanned images (less common).
- Extraction of numerical data and its context involves analysis of the document structure and tables.
- Extraction of dates utilizes Exerica’s proprietary Natural Language Processing engine to parse financial slang and special terminology to extract fiscal dates for the text.
- Establishing links between numerical data points inside the document.
- Establishing links between datapoints in different documents of the same company/publisher – first based on the high confidence numerical context and then based in the linguistic context.
- Saving the data sets into the database.