back
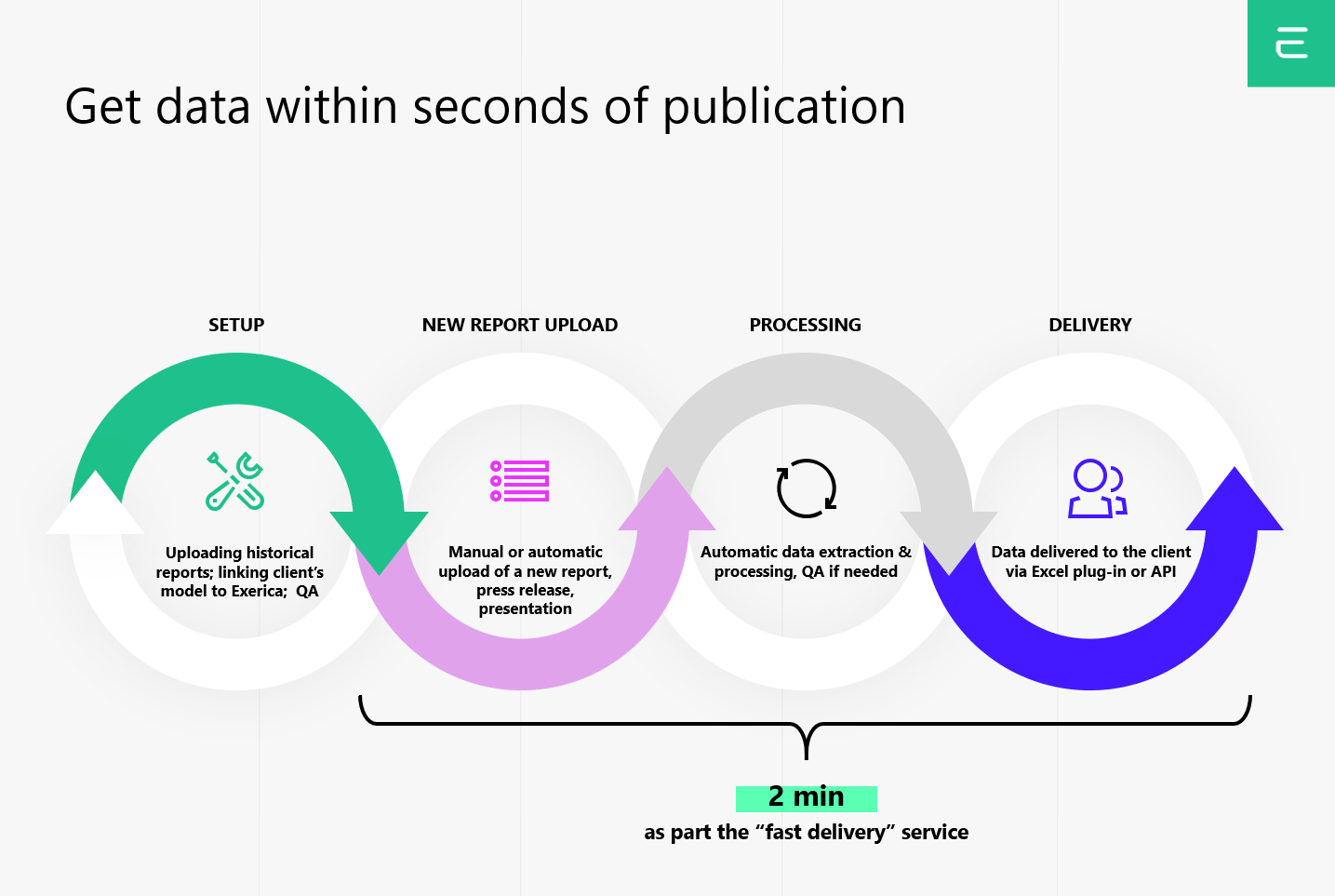
Data delivered in seconds
It normally takes between one to five minutes to process a document with Exerica’s algorithms. As part of the automated pipeline all numerical data gets extracted, analysed and structured to make it available to end-users via our API and Excel plugin.
The key processes are these:-
- Optical recognition is the greatest variable in the process. It usually takes a few seconds to extract text from a pdf with a text layer (which is the vast majority of financial publications these days) but may take a few minutes to process scanned images.
- Extraction of numerical data and its context involves analysis of the document structure and tables.
- Extraction of dates utilizes Exerica’s proprietary Natural Language Processing engine to parse financial slang and special terminology to extract fiscal dates for the text.
- Establishing links between numerical data points inside the document.
- Establishing links between datapoints in different documents of the same company/publisher – first based on the high confidence numerical context and then based in the linguistic context.
- Saving the data sets into the database.
Maxim Miller